
[딥러닝]DropOut
카테고리: DeepLearning
1. Drop-Out의 정의
Drop-Out은 Deep Learning 모델을 학습할때, Layer에 있는 노드들이 서로 Edge로 연결되어 있는데 이 Edge들을 0에서 1사이의 확률로 제거하는 것이다. 즉, Layer간 연결된 뉴런을 일정 확률로 끊어버리는 기법이다. 기존의 모든 노드들이 연결되어 있으면 이 Layer를 FC, Fully Connected Layer라고 부른다. 이때, Drop-out rate에 따라 끊어지는 뉴런의 개수가 랜덤하게 결정된다. Drop-out Rate는 Hyperparameter이다.
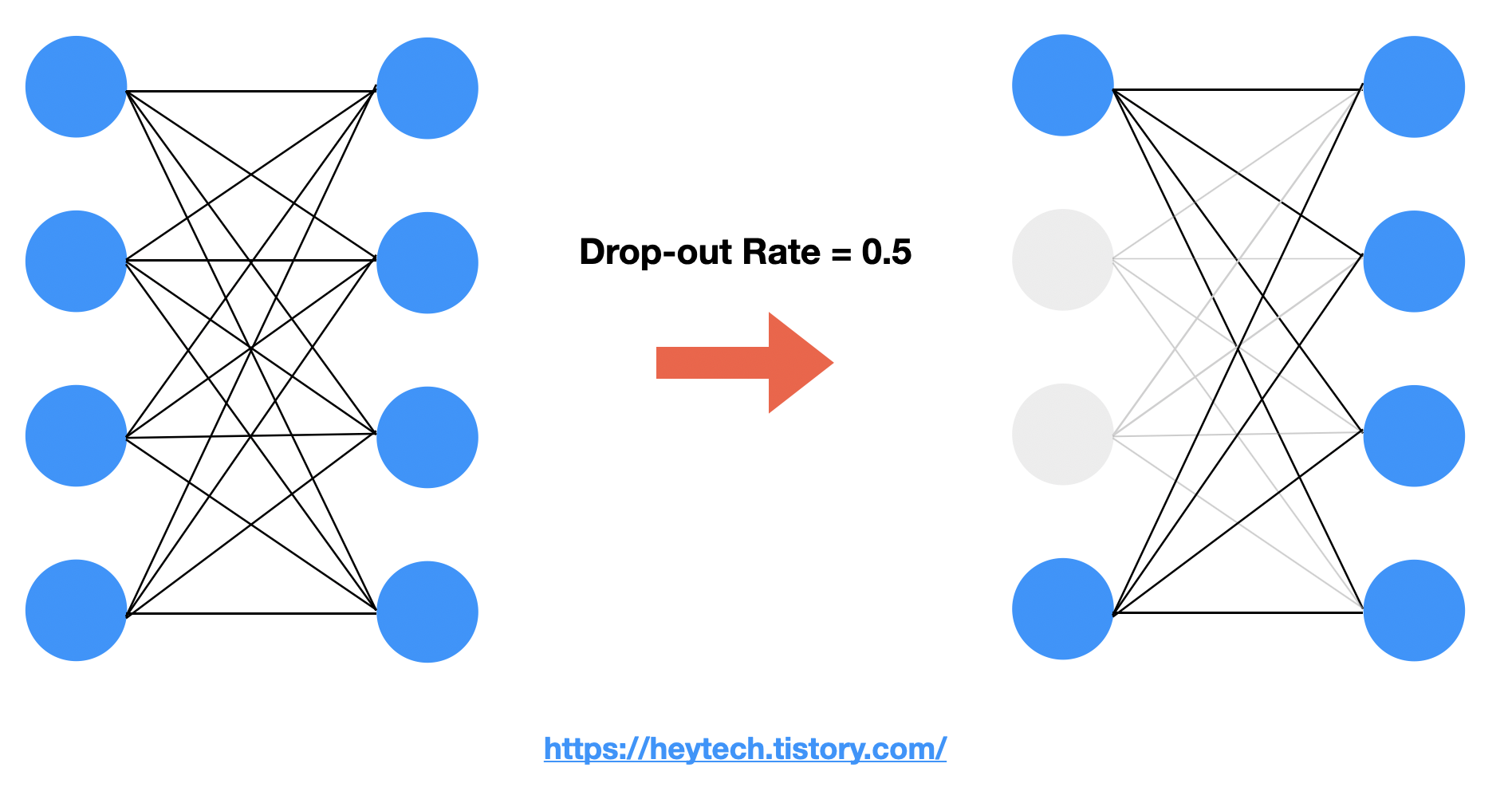
2. Drop-out의 사용 목적
Drop-out의 사용 목적은 바로 과대적합(Overfitting)을 방지하기 위함이다.

위의 노란색 박스 안에 있는 Drop-Out이 적용된 FC layer는 하나의 Realization 또는 Instance라고 부른다. 각 Realization이 일부 뉴런만으로도 좋은 출력값을 제공할 수 있도록 최적화되었다고 가정했을 때, 모든 realization 각각의 출력값에 평균을 취하면(이 과정을 Ensemble, 앙상블 이라고 한다.) 오른쪽 그림과 같이 완전한 FC를 얻을 수 있다. 특히Drop-out으로 Overfitting이 되지 않은, 어떠한 weight에 편향되지 않은 FC layer를 얻을 수 있다.
만약 Drop-out을 적용하지 않고 모델을 학습하면, 해당 Feature에 가중치가 가장 크게 설정되어 나머지 Feature에 대해서는 제대로 학습되지 않을 것이다. 반면, Drop-out을 적용하여 상관관계가 강한 feature를 제외하고 학습해도 좋은 output을 얻을 수 있도록 최적화되었다면, 해당 feature에만 출력값이 좌지우지되는 과대적합(Overfitting)을 방지하고 나머지 feature까지 종합적으로 확인할 수 있게 된다. 이것이 Model generalization 관점에서 Drop-out을 사용하는 이유이다.
3. Mini-batch 학습 시 Drop-out

위의 그림과 같이 FC layer에서 Mini-batch 학습 시 Drop-out을 적용하면 각 batch별로 적용되는 것을 알 수 있다. 즉, 각 layer별로 다른 edge들이 끊어지게 된다.
4. Test시 Drop-out

Test 단계에서는 모든 뉴런에 scaling을 적용하여 동시에 사용한다. 여기서 는 activation function, 는 drop-out rate를 의미한다. Drop-out rate를 활용해 scaling 하는 이유는 기존에 모델 학습 시 drop-out rate 확률로 각 뉴런이 꺼져 있었다는 점을 고려하기 위함이다. 즉, 같은 출력값을 비교할 때 학습 시 적은 뉴런을 활용했을 때(상대적으로 많은 뉴런이 off 된 경우)와 여러 뉴런을 활용했을 때와 같은 scale을 갖도록 보정해 주는 것이다.
Reference
[딥러닝] Drop-out(드롭아웃)은 무엇이고 왜 사용할까?
댓글 남기기